The text-to-speech technology involves the process of converting written text into spoken audio. The main applications of this technology are entertainment, education, and communication. Beginners to this technology think about how it has evolved over the years especially from the synthesized voices to the modern natural language processing systems to produce human-like speech with accents, emotion, and intonation. You can focus on the resources dedicated to exploring the technical frontiers of text-to-speech innovation and get an overview of the challenges in the TTS algorithm development.
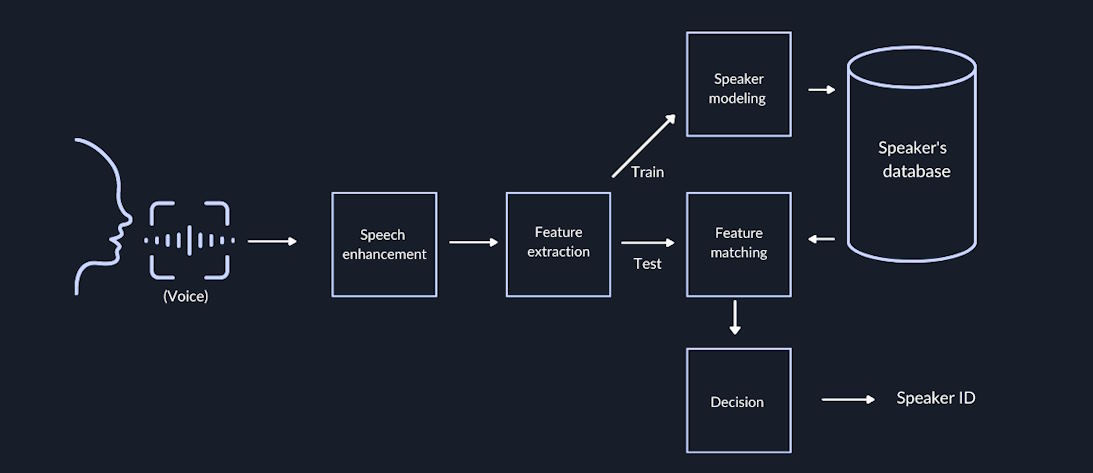
Focus on the early origins of the TTS technology
This early TTS technology’s applications were for accessibility purposes especially helping reading disabilities to access written content and visually impaired people to access the content.
The later TTS technology was used for education, entertainment, and communication purposes like creating audiobooks, voice records, and voice assistants. You have to focus on effective and successful techniques for overcoming complexities in text-to-speech algorithm development at this time.
The principles behind the early TTS models are formant synthesis and concatenative synthesis. You can concentrate on advancements in TTS technology in detail. Synthetic voices are created by speech synthesis applications especially TTS systems for converting text and other symbolic representations into speech. The voice synthesis is used in communication, entertainment, and education-related applications.

Prefer and use the world-class TTS technology
Realistic methods for tackling hurdles in crafting natural-sounding speech synthesis encourage everyone in the competitive business sector to make an informed decision about using the TTS technology. Synthetic voice development involves several stages, especially from rule-based methods to data-driven methods. Rule-based methods use pre-recorded speech units and mathematical models to generate speech sounds from scratch. Data-driven methods use large-scale speech corpora and machine learning algorithms to learn the mapping between text and speech features.